概述
当前主要的实现了OpenTracing框架除了之前提到的zipkin,另一个则是今天要介绍的jaeger。jaeger作为一个当下流行的服务跟踪框架,同时还加入了CNCF,主流服务网格解决方案ISTIO也在0.8版把jaeger作为其官方演示Service Tracing的默认框架,所以还是有必要学习了解的。
首先参照着jaegerGITHUB项目地址的介绍,简单介绍一下jaeger的主要特性。
- 高扩展性
- OpenTracing原生支持
- 多存储后端支持
- 主流WEB UI界面
- Cloud Native开发支持
- 所有组件支持Prometheus监控
下面以JAVA作为客户端语言接入为例,简单演示一下整个部署及对接流程。
架构
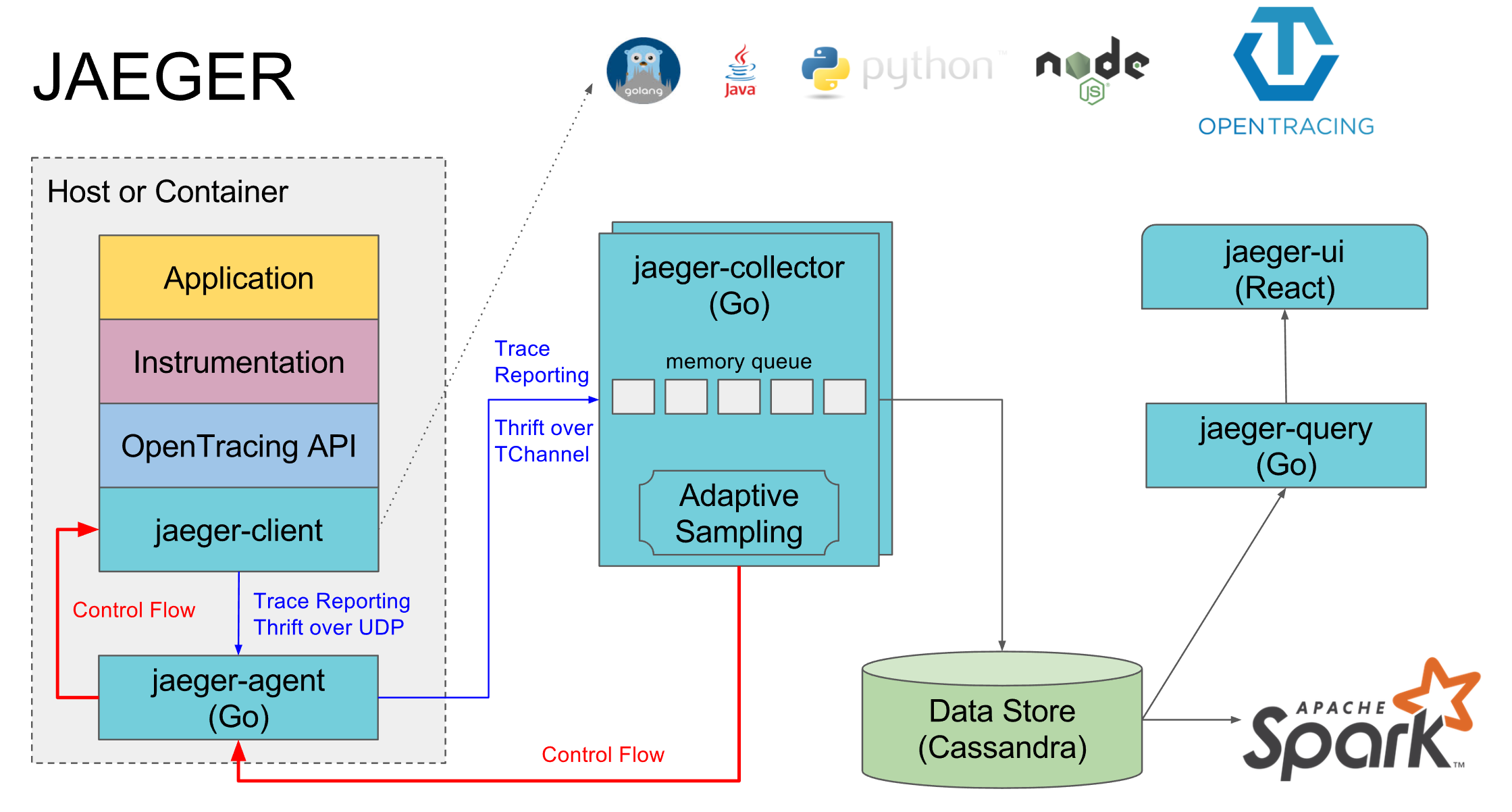
服务端分为三个组件,jaeger-agent(代理)、jaeger-collector(收集器)及jaeger-query(UI)。jaeger-agent为jaeger-client和jaeger-collector间的代理,解耦的中间层。jaeger-client收集跟踪信息并以UDP传输的形式发给jaeger-agent,jaeger-agent接收后,以分批形式通过TChannel(RPC)传输给jaeger-collector的缓冲队列。jaeger-collector从队列中取出跟踪信息并做持久化(或直接内存存储)。而作为以UI的jaeger-query从相应的持久化数据库拉取数据并作展示,这里需要注意的是当数据以内存存储时,UI上的依赖关系图是可以做到实时变化的,但以数据库做持久化时,依赖关系的产生需要由spark以一个定时任务的形式分析产生。
服务端部署
一体化部署
以下部署方式为docker容器部署,并且jaeger-agent,jaeger-collector及jaeger-query三个组件一体化部署,部署方式较为简单,但由于数据内存存储,故不适合生产环境部署。
docker run -d -e COLLECTOR_ZIPKIN_HTTP_PORT=9411 -p 5775:5775/udp -p 6831:6831/udp -p 6832:6832/udp -p 5778:5778 -p 16686:16686 -p 14268:14268 -p 9411:9411 jaegertracing/all-in-one:latest
这里需要说明一下,各端口的作用,如下表所示:
| 端口 | 协议 | 组件 | 作用 |
|---|---|---|---|
| 5775 | UDP | agent | 接收zipkin以TCompactProtocol协议序列化的数据 |
| 6831 | UDP | agent | 接收jaeger以TCompactProtocol协议序列化的数据 |
| 6832 | UDP | agent | 接收jaeger以TBinaryProtocol协议序列化的数据 |
| 5778 | HTTP | agent | 获取服务配置 |
| 16686 | HTTP | query | 前端页面入口 |
| 14268 | HTTP | collector | 直接从客户端接收jaeger thrift序列化的数据 |
| 9411 | HTTP | collector | zipkin兼容端口 |
独立部署
下面以docker为部署方式说明,数据库为ES。
搜索引擎数据ES部署网上的部署教程很多,此处不再赘述。以下为部署采集组件jaeger-collector:
docker run -d \
--rm \
-p 14268:14268 \
-p 9411:9411 \
jaegertracing/jaeger-collector \
/go/bin/collector-linux --es.server-urls=http://localhost:9200
接着部署代理组件jaeger-agent:
docker run -d \
--rm \
-p 5775:5775/udp \
-p 6831:6831/udp \
-p 6832:6832/udp \
-p 5778:5778/tcp \
jaegertracing/jaeger-agent \
/go/bin/agent-linux --collector.host-port=jaeger-collector.jaeger-infra.svc:14267
最后部署WEB UI组件jaeger-query:
docker run -d \
--rm \
-p 16686:16686
jaegertracing/jaeger-query \
/go/bin/query-linux --es.server-urls=http://localhost:9200
JAVA客户端接入
jaeger官方有提供客户端用于收集跟踪数据及发往jaeger-agent或jaeger-collector。假如项目使用了SpringBoot或者SpringCloud,可以使用io.opentracing开发的依赖,直接引入及配置参数即可,不用额外编码。
SpringBoot
maven引入依赖如下:
<dependency>
<groupId>io.opentracing.contrib</groupId>
<artifactId>opentracing-spring-jaeger-web-starter</artifactId>
<version>0.1.5</version>
</dependency>
配置参数如下:
opentracing:
jaeger:
udp-sender:
host: localhost
port: 6831
log-spans: false #是否发送spans时输出日志,生产环境建议关闭该项,调试时可以开启
probabilistic-sampler:
sampling-rate: 0.01 # 概率采集的概率设置,范围为0~1的小数,生产环境一般不全量采集
spring:
web:
skip-pattern: "/<your-url-prefix>/*|/api-docs.*|/autoconfig|/configprops|/dump|/health|/info|/metrics.*|/mappings|/swagger.*|.*\\.png|.*\\.css|.*\\.js|.*\\.html|/favicon.ico|/hystrix.stream" # WEB跟踪的URL过滤名单
enabled: true # 是否开启web跟踪,即项目自身暴露的web接口
client:
enabled: true # 是否开启web clientg跟踪,即resttemplate调用外部接口
SpringCloud
maven引入依赖如下:
<dependency>
<groupId>io.opentracing.contrib</groupId>
<artifactId>opentracing-spring-cloud-starter-jaeger</artifactId>
<version>0.1.13</version>
</dependency>
配置参数如下:
opentracing:
jaeger:
udp-sender:
host: localhost
port: 6831
spring:
cloud:
jdbc:
enabled: true
同样地,先配置jaeger的接受端口,另外还可以配置开启相应的跟踪功能,假如项目内用到JDBC则可以跟踪JDBC的调用链信息,除外还有Mongo、JMS、WebSocket等功能,默认是所有的功能都开启的。
从简化依赖的角度看,最好是项目中实际用到了什么,就引入对应功能的跟踪依赖,避免使用"全家桶"使得项目依赖变得臃肿。以下是单独功能的跟踪依赖展示:
| function | groupId | artifactId | version |
|---|---|---|---|
| web | io.opentracing.contrib | opentracing-spring-jaeger-web-starter | 0.1.5 |
| mongo | io.opentracing.contrib | opentracing-spring-cloud-mongo-starter | 0.1.15 |
| jdbc | io.opentracing.contrib | opentracing-spring-cloud-jdbc-starter | 0.1.15 |
| rabbitMQ | io.opentracing.contrib | opentracing-spring-rabbitmq-starter | 0.1.0 |
| websocket | io.opentracing.contrib | opentracing-spring-cloud-websocket-starter | 0.1.15 |
| feign | io.opentracing.contrib | opentracing-spring-cloud-feign-starter | 0.1.15 |
| zuul | io.opentracing.contrib | opentracing-spring-cloud-zuul-starter | 0.1.15 |
| hystrix | io.opentracing.contrib | opentracing-spring-cloud-hystrix-starter | 0.1.15 |
整体UI效果展示
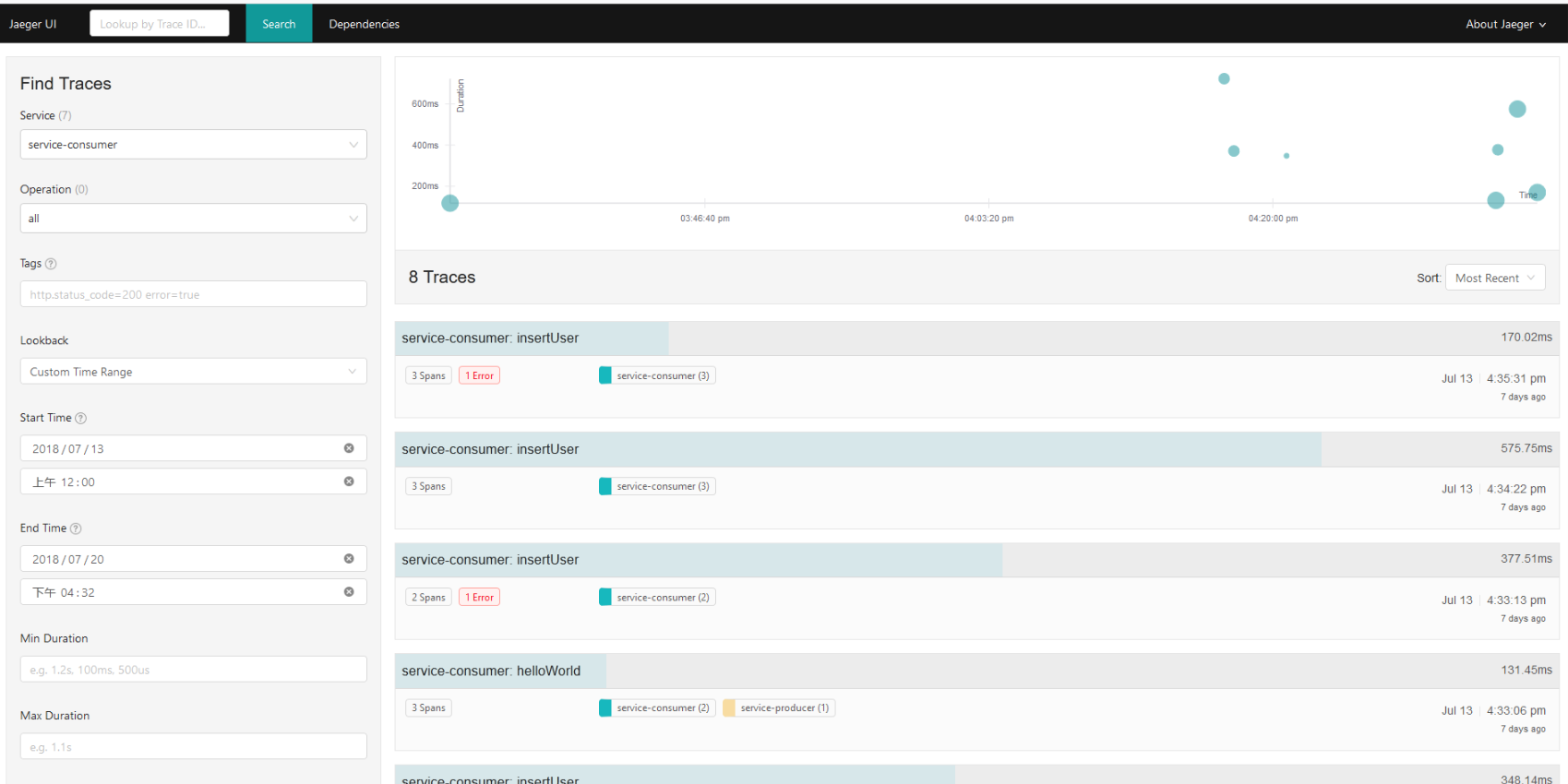
首页展示如下,右上方的图表展示了各条调用链,一个点为一条链,点的大小代表了调用链整体时间的长短;
右下方的为各调用链按照排序方式的简要展示,信息主要为整体时间、span数量及调用链是否有错误产生;
左侧是筛选条件的选择和设置,可以筛选符合条件的调用链。
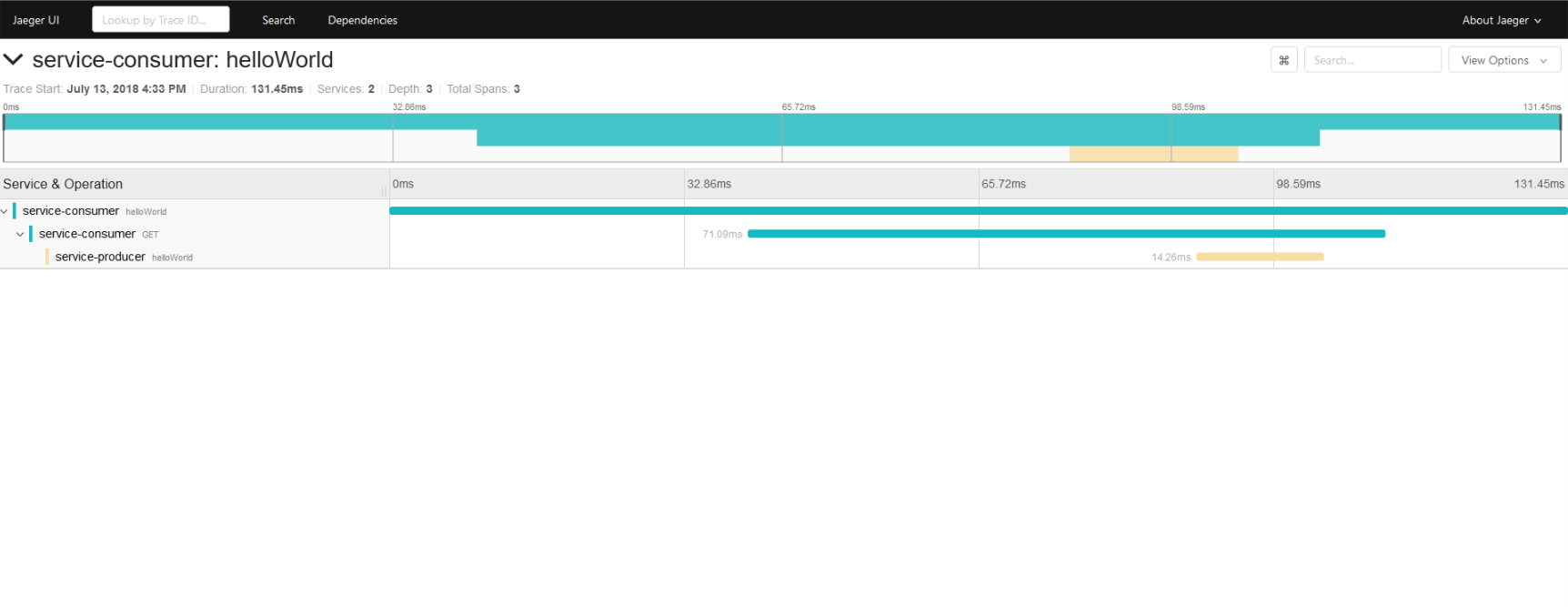
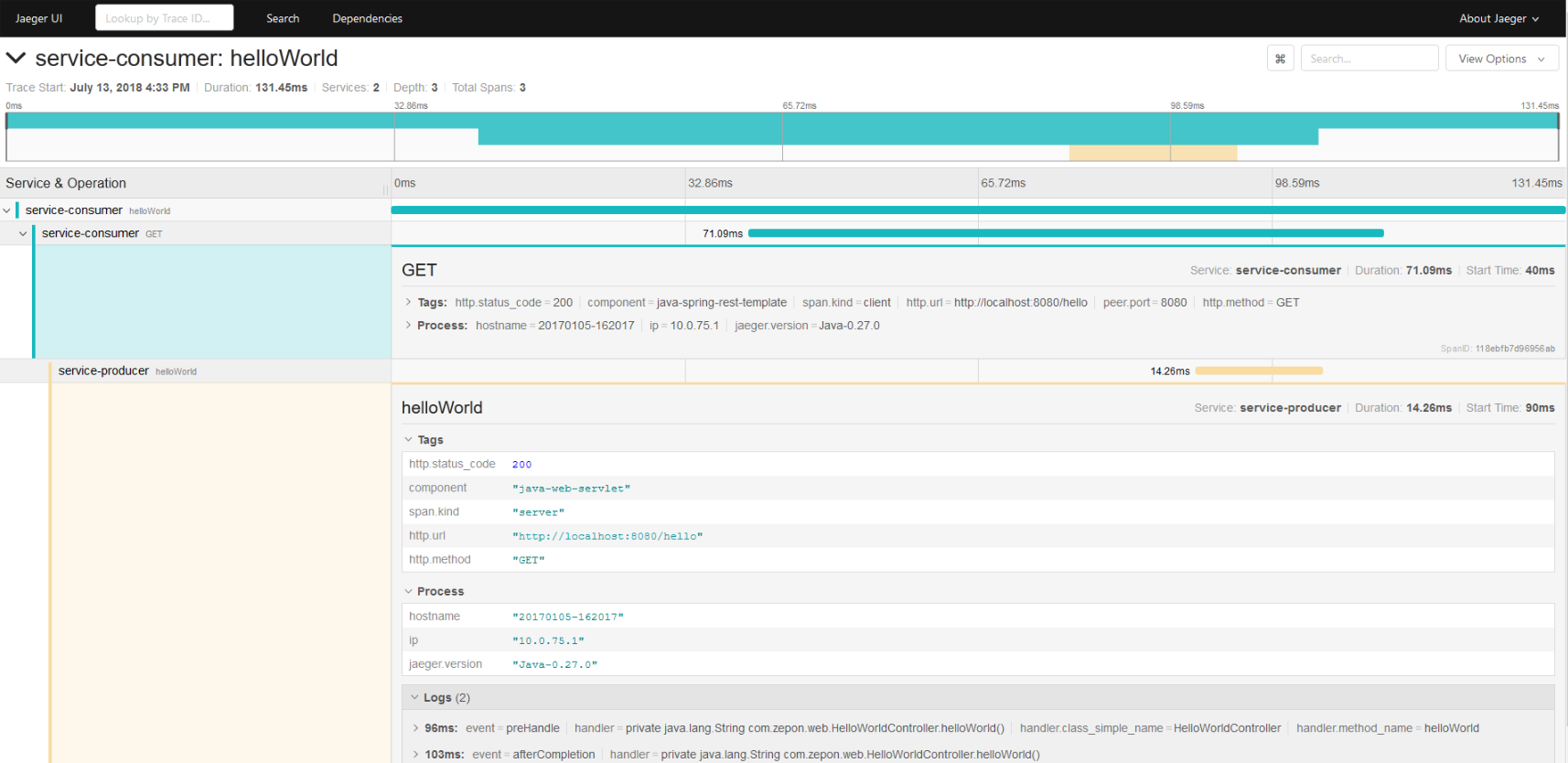
调用链的具体展示如下,最上侧图形化展示了各span的用时,下方展开则可以看到各span内包含的具体信息,如HTTP状态码,URL地址,METHOD,ip等信息。
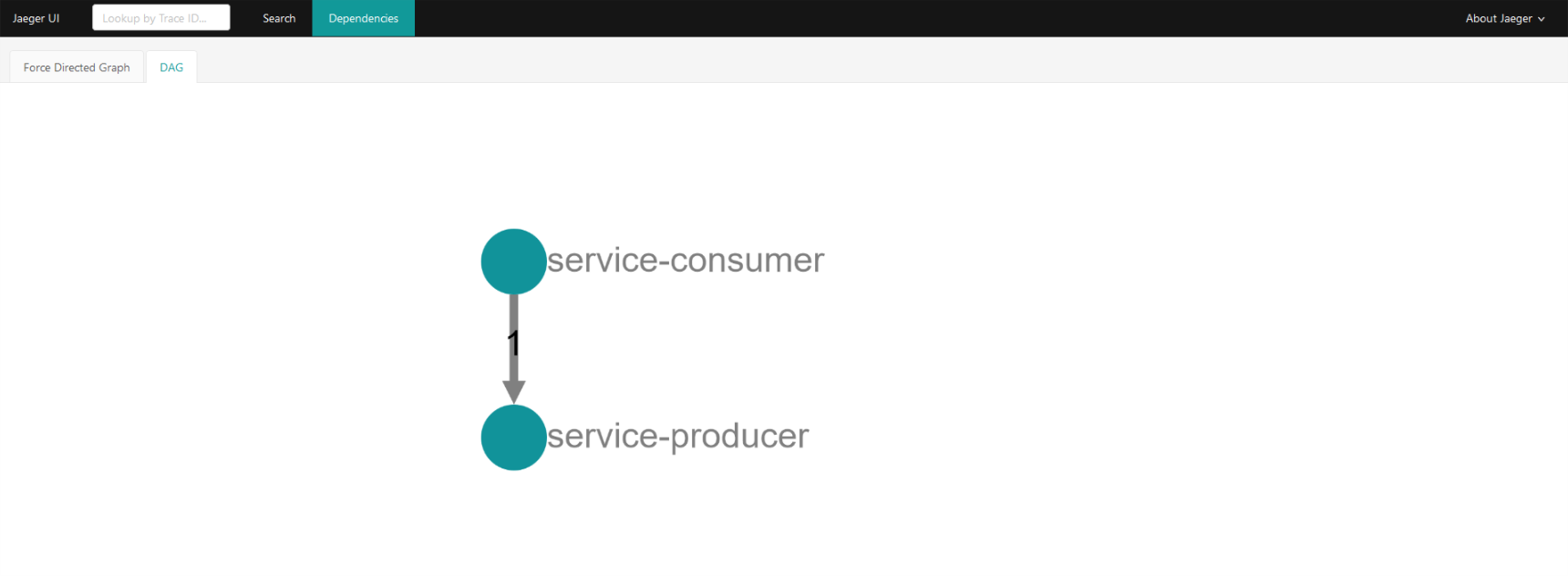
服务间依赖关系图如下,箭头中间的数字代表了调用成功的次数。