概述
在微服务架构下,随着业务的发展,微服务的数量增多,会造成服务间的调用关系难以梳理。在错综复杂的调用关系中,一个由客户端发起的请求可能需要后端多次的微服务调用完成的,任何一个单元的调用延迟或者失败都有可能造成最终请求失败。因此出于发现链路性能瓶颈以及跟踪调用失败原因,对于微服务的调用链进行跟踪就显得尤为重要了。
微服务跟踪的解决方案有很多,比如Google的Dapper,微博的fiery,京东的Hydra,淘宝的鹰眼等,部分解决方案有开源,当前主流的开源框架是Twitter的zipkin及Uber的jaeger。今天以zipkin为示例。
结构
整体架构示意图如下
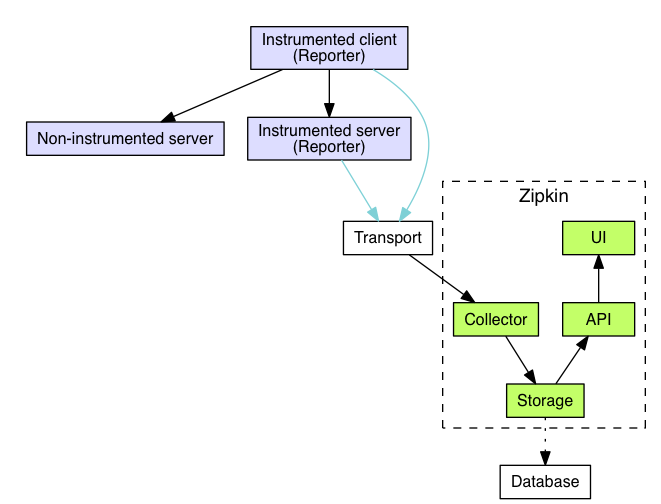
主要分为如下
-
Zipkin Client: zinkin埋点客户端,目前客户端官方及第三方提供的支持有java,C,python,JavaScript等,具体内容可以点击此处查看。
-
Transport:传输方式,可以是直连的http请求,也可以是提供缓存的消息中间件,有Http, Kafka, Scribe等
-
Database:跟踪数据的存储模块,默认是内存,也可以配置为mysql、elasticsearch或Cassandra持久化。
-
Zipkin Server:由Collector、API、Storage及UI组件组成的服务端,用于收集、存储、聚合及展示跟踪数据
此次示例,传输模块选用的是kafaka,存储模块为elasticsearch,客户端选用为java。
Kafka
准备好用于缓冲服务跟踪日志的消息中间件kafka,网上关于如何安装kafka的教程有很多,此处不再赘述。
ElasticSearch
准备用于持久化服务跟踪日志的搜索引擎数据库ES。同样地,网上也有许多ES的安装教程,ES的安装也比较简单,此处不赘述安装过程。
Zipkin Server
安装Zipkin Server用于对服务跟踪日志进行聚合,展示,查询。此处展示的是docker的安装方式,k8s安装方式自行类推。
docker run -d --name zipkin-server \
-p 9411:9411 \
-e "KAFKA_BOOTSTRAP_SERVERS=your-kafka-address" \
-e "STORAGE_TYPE=elasticsearch" \
-e "ES_HOSTS=your-es-host" \
-e "ES_INDEX=zipkin" \
-e "ES_INDEX_SHARDS=1" \
-e "ES_INDEX_REPLICAS=1" \
zipkin:latest
Zipkin Client(java)
服务提供方
加入依赖
Spring Boot 版本为1.5.13。
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.5.13.RELEASE</version>
<relativePath/>
</parent>
引入指定版本的Spring Cloud的dependencyManagement。
<properties>
<spring-cloud.version>Edgware.RELEASE</spring-cloud.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
引入依赖,包括Spring Cloud Sleuth和Kafka传输的支持依赖Spring Stream Kafak以及web依赖。
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-kafka</artifactId>
</dependency>
</dependencies>
配置
spring:
application:
name: service-producer # 配置应用名称
kafka:
bootstrap-servers: localhost:9092 # 缓冲kafka地址
sleuth:
sampler:
percentage: 1 # 设置采样频率,默认为0.1,设置为全采样,便于观测,实际项目中根据具体情况设置
server:
port: 8080
编写接口
编写接口服务用于另一个应用调用。
@RestController
public class HelloWorldController {
@GetMapping("/hello")
private String helloWorld() {
return "Hello World!";
}
}
服务调用方
加入依赖
同服务提供方的依赖相同,此处不再赘述。
配置
spring:
application:
name: service-consumer
kafka:
bootstrap-servers: localhost:9092
sleuth:
sampler:
percentage: 1
server:
port: 8090
调用接口
调用接口提供方的接口服务。
@Component
public class HelloWorldApi {
private final RestTemplate restTemplate;
public HelloWorldApi(RestTemplateBuilder restTemplateBuilder) {
this.restTemplate = restTemplateBuilder.defaultMessageConverters().setConnectTimeout(60000).build();
}
public String helloWorld() {
return restTemplate.getForObject("http://localhost:8080/hello", String.class);
}
}
对外暴露web接口服务,用于触发调用链。
@RestController
public class ConsumerController {
private final HelloWorldApi helloWorldApi;
public ConsumerController(HelloWorldApi helloWorldApi) {
this.helloWorldApi = helloWorldApi;
}
@GetMapping("/hello")
public String helloWorld() {
return helloWorldApi.helloWorld();
}
}
效果展示
访问接口http://localhost:8090/hello触发调用链。可以在Zipkin Server的UI地址http://localhost:9411查看到如下的效果图。
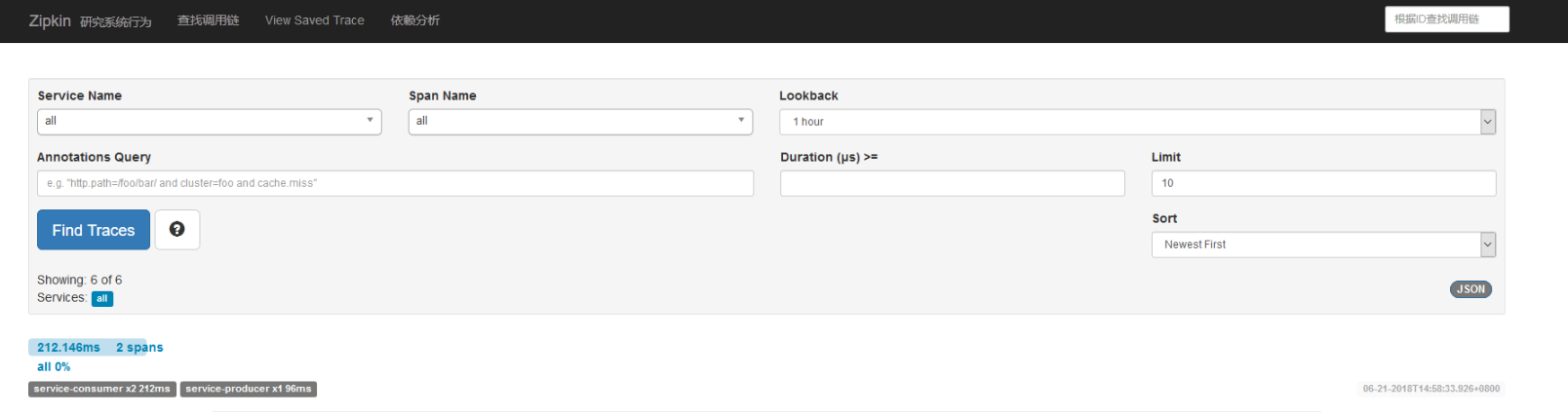
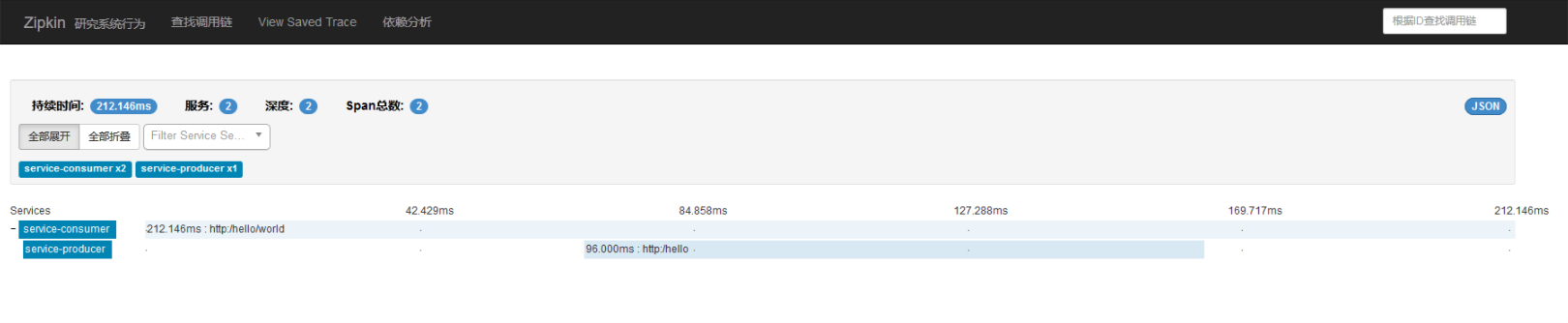
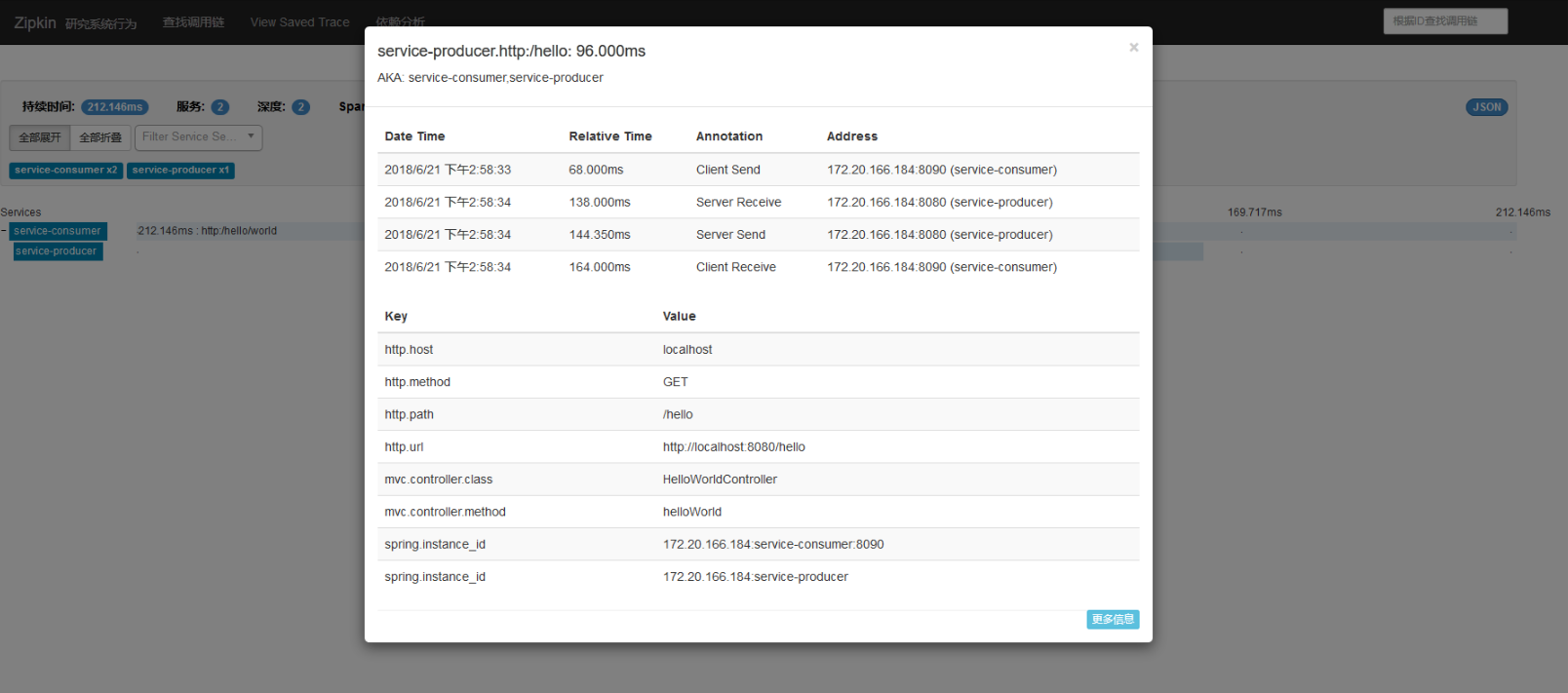
依赖关系
需要注意的是,我们使用的存储模块是ES,所以一段时间内的服务调用关系图是无法直接得到的(使用内存存储可以直接得到)。我们需要使用Zipkin官方提供的zipkin-dependencies来生成依赖关系图。以下以java jar及k8s定时任务的形式展示,其他形式请自行类推。
# ex to run the job to process yesterday's traces on OS/X
$ STORAGE_TYPE=elasticsearch ES_HOSTS=your-es-host ES_INDEX=zipkin ES_NODES_WAN_ONLY=true java -jar zipkin-dependencies.jar `date -uv-1d +%F`
---
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: zipkin-server-dependencies
namespace: brp
spec:
schedule: "57 23 * * *" # 设置定时任务的执行时间
jobTemplate:
spec:
template:
spec:
containers:
- name: zipkin-server-dependencies
image: docker.io/openzipkin/zipkin-dependencies:latest
imagePullPolicy: IfNotPresent
env:
- name: STORAGE_TYPE
value: "elasticsearch"
- name: ES_HOSTS
value: "your-es-host"
- name: ES_INDEX
value: "zipkin"
- name: ES_NODES_WAN_ONLY
value: "true"
restartPolicy: OnFailure
---
注: zipkin-dependencies先从ES中获取名为zipkin:yyyy-MM-dd的index数据,yyyy-MM-dd为UTC时间对应的年月日。
总结
使用Zipkin可以收集服务调用链上的跟踪信息,帮助我们了解服务的性能瓶颈,进而优化服务。但这种客户端埋点的形式其实还是让服务跟踪侵入了应用,微服务架构中服务网格管理了网格中微服务中的进出口网络流量,由网格来统计跟踪信息比较合适。这种方式统计还有一个优势在于应用不用注入埋点的客户端依赖,即不侵入应用,服务网格Istio提供了这样的服务跟踪功能。istio的性能及稳定性……╮(╯▽╰)╭。
另外,Kong的下一个版本0.14提供了Zipkin的监控插件,即对于REST API服务应用来说,服务跟踪的调用链的起点可以从网关开始了。从网关到后端服务的时延统计也可以得到了。
最后,个人感觉假如服务跟踪信息只是在Zipkin的UI简单地展示每条具体调用链的具体时间和失败与否,并没有把服务跟踪信息的价值完全地展现出来,应该对这些零散的调用链的信息进一步分析,挖掘更直观的信息。